
Why We Systematically Test Every Model and Prompt We Use
Here's what happens in most organisations using LLMs in production. Someone crafts a prompt, tests it a few times, sees reasonable output, and ships it. Three months later, they discover the model has been quietly failing in specific edge cases, formatting responses incorrectly for certain inputs, or ignoring key instructions when the context gets long. The failures weren't obvious because no one was checking systematically.
This isn't a story about bad prompts. It's about not treating LLM deployment like traditional software when it requires something different.
What Actually Fails
In February 2024, Air Canada's chatbot gave incorrect information about bereavement fares. The chatbot is now offline. The significant part of this is it wasn't a hallucination where the model invented whole new “facts”. Instead, the chatbot provided plausible-sounding policy information that did not align with the company's actual terms.
This is one type of failure. There are others that are equally problematic: models that follow instructions inconsistently, maintain inappropriate tone in specific contexts, handle edge cases poorly, ignore formatting requirements, provide inappropriately scoped responses, or behave unpredictably under varied conditions. Each dimension can fail independently. Manual spot-checking will miss most of them.
What the Pattern Looks Like
Simon Willison, who writes extensively about practical LLM development, coined the term "vibe coding" for accepting AI-generated code without thorough review. It's fine for throwaway projects. For production systems, he's direct: "Vibe coding your way to a production codebase is clearly risky."
The same applies to prompt engineering. Relying on intuition and spot-checks rather than systematic evaluation is vibe-checking your way to production.
The major AI providers follow different principles. OpenAI runs extensive red-teaming exercises—testing against jailbreak prompts, offensive completions, role overrides. Anthropic tests for rule adherence, response justification, value alignment across ambiguous prompts. Both emphasise that testing isn't finished when you ship. It's ongoing as models evolve.
Why Traditional Testing Falls Short
Here's the fundamental challenge: LLMs are non-deterministic. The same prompt can yield different valid answers. Traditional software testing assumes that given input X, you always get output Y. With LLMs, you might get Y, or a slightly different Y, or occasionally Z.
This means you can't just test for exact outputs. You need to test for output quality, accuracy, safety, and behaviour under imperfect conditions.
Why Should I Care?
Industry analysis estimates companies lose $1.9 billion annually from undetected LLM failures in production. CNET published finance stories with AI-generated errors, damaging their reputation in ways that persist after corrections. Apple suspended its AI news feature in January 2025 after producing misleading summaries.
These failures share a pattern: organisations relied on manual review and spot-checks rather than systematic testing. A human reviewer catches obvious problems but misses subtle inconsistencies, formatting violations, tone shifts, or instruction-following failures on test case #247.
The compounding effect is the real problem. Each failure erodes trust. Users become less likely to rely on your AI features. You've invested in capabilities people actively avoid.
What Testing Actually Looks Like
Anthropic's documentation on creating evaluations emphasises three principles:
Be task-specific: Design evaluations that mirror your actual task distribution, including edge cases. Don't just test the happy path.
Automate when possible: Structure questions to allow automated grading. More questions with slightly lower signal beats fewer questions with perfect human grading.
Encourage reasoning: When using LLMs to grade other LLM outputs (LLM-as-judge), ask them to think through their reasoning first, then discard it. This improves evaluation performance.
OpenAI takes a similar approach, running GPT models inside sandboxed environments where they must make decisions using memory, tool calls, and multi-step reasoning. They validate not just what the model says, but how it behaves when things get complex.
Building Evaluation Systems
The LLM evaluation ecosystem has grown significantly. Open-source frameworks like DeepEval, Promptfoo, and RAGAS offer automated metrics and standardised benchmarks. Commercial platforms like Braintrust, LangSmith, and Confident AI provide polished interfaces and collaboration features.
But here's what we've observed: the evaluation systems that drive improvement are almost always custom-coded.
Why? Effective evaluation requires deep specificity about what matters in your domain. Generic metrics like BLEU scores might correlate with quality, but they don't measure what actually matters to your users.
Here's what comprehensive evaluation looks like to us:

Six models tested against nearly 300 test cases, measuring quality scores, compliance rates, and cost efficiency
This system measures:
Domain-specific quality based on business strategy frameworks, not generic metrics
Compliance rates checking adherence to formatting rules (bold tag usage, paragraph structure)
Cost efficiency comparing performance per dollar spent
Statistical significance using proper hypothesis testing to distinguish real differences from noise
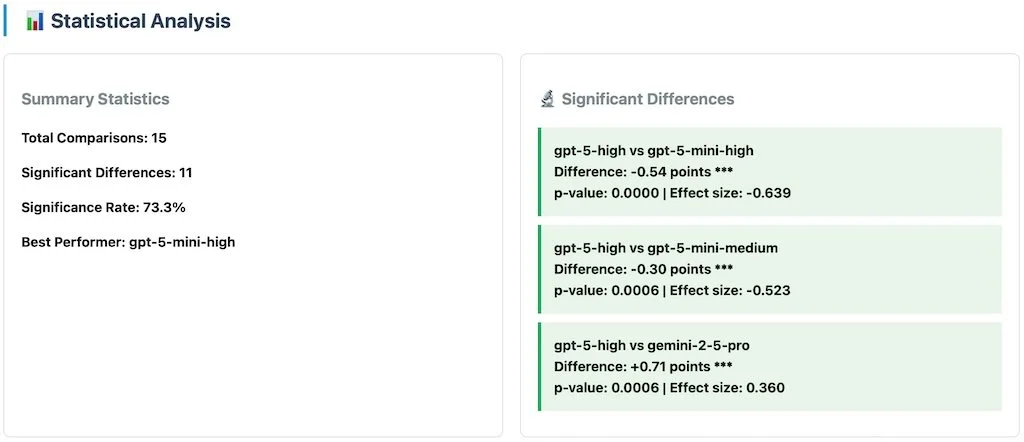
P-values and effect sizes show which performance differences are meaningful vs. random variation

Automated detection of length bias, positional bias, keyword bias, and temporal bias
The bias detection matters. It's meta-evaluation that tests whether your testing system itself is flawed. Are longer responses unfairly rewarded? Do later evaluations score differently due to fatigue? These patterns indicate your evaluation framework might be measuring the wrong things.
Why Custom Usually Wins
The evaluation system shown above uses elements from open-source frameworks but is fundamentally custom-built. It needs to be, because it's testing:
Specific business strategy frameworks and methodologies
Exact formatting requirements unique to the client
Domain-specific content quality that no generic metric captures
Client-specific style preferences that evolve over time
No off-the-shelf platform evaluates these criteria out of the box. By the time you've written custom evaluation functions and analysis logic, you've essentially built a custom system - just with more overhead.
The practical approach:
Start with frameworks like DeepEval or Promptfoo to understand evaluation patterns
Borrow concepts like LLM-as-judge and statistical testing methodologies
Build custom when you understand your specific requirements
Instrument everything so you can continuously improve
Your evaluation system should evolve with your understanding of what good output looks like. This requires code you control.
The Practical Take
We're past the experimental phase with LLMs. These systems handle customer service, generate content, make recommendations, and increasingly drive critical business functions. The companies building them emphasise rigorous, ongoing testing as essential for responsible deployment.
Your LLM applications deserve the same approach. Start with existing frameworks to understand evaluation patterns. Borrow their methodologies and best practices. But recognise that solving your specific evaluation needs will likely require custom code that encodes your quality standards, adapts to your evolving requirements, and integrates with your production systems.
Build it. Instrument it. Evolve it. It's far less expensive than discovering your LLM has been failing in subtle ways for months, degrading user experience and eroding trust in ways you can't easily repair.